introduction to big data system
1-2. introduction
跟传统数据分析处理比起来,有三个明显区别。
- 采样计算变成全数据计算。采样
- 精确的数据变为带有噪音的数据。
- 重点考虑因果变为求出相关关系。
之所以能这么做是因为现有的硬件环境跟上来了(摩尔定律)。然而,摩尔定律必然会有它的天花板,不能一直持续下去;而另外一方面数据量增长速度,超过了摩尔定律。所以只能考虑并行/分布式的处理方式。
并行计算/分布式计算很火,但是我们需要考虑的一件事就是是否有必要。因为超频的存在,通过加大电压,可以使得处理器频率变高,性能提升。一般来说,频率和电压的平方或者三次方成正比。所以如果一个并行系统,需要四个处理器,提升30%的性能,那么其实完全没有必要,加电压1.3倍,耗能最多增加2.2倍,而4个处理器需要4倍。
Amdahl’ Law
并行部分比例是p,$1-p + \frac{p}{n}$, 当n无限大的时候,时间为1-p,加速比最多能达到$\frac{1}{1-p}$。这是较为悲观的一种规则。
Gustafson’ Lasw
认为问题的规模是不固定的(和Amdahl相反),实际上也是这样的。为了提高精度,需要更多的数据。以为因为硬件条件的限制,数据量较少;当机器能力上去之后,数据量会增多。
所以我们可以认为,问题的规模是$S = a(n) + p(1-a(n))$,a表示串行部分,p表示处理器数量,n表示问题的规模。所以,当a(n)为常量的时候,加速比可以趋向于p。这是一个很乐观的规则。
真实系统的性能在两条规则中间。
并行的问题有:
- 并行度小,有时候数据有先后依赖,有的部分只能串行;发现并行性对程序员要求很高。
- load balance
- 同步问题
线程内存模型
线程的概念勿用多说。这里提一下线程的内存模型。我们知道,一个进程是一个独立的单元,内部可能会有多个线程。线程共享一个堆栈,代码段,虚拟地址空间,文件操作符;而线程有自己单独的stack,寄存器,pc等。但是线程之间可以互相访问彼此的stack!
上述是操作系统层面,再看看编译里是如何做的。以POSIX pthread为例,分为三种变量:全局变量;局部非静态变量;局部静态变量。只有局部非静态变量会在每个线程里有一份单独的空间,其它两种全局都只有一个!
为了防止数据竞争,所以可能需要加锁。
Openmp
pthread性能很好,灵活性也很好,基本所有的多线程功能都能实现。但是有时候并没有那么好用,可编程性差,而且在windows上没法用。所以openmp这时候就比较好用了。
需要记住的是openmp四种线程调度模式。以及#pragma omp critical表示临界区域。
3. MPI
上一章说的都是单进程多线程。MPI全称是消息传递接口,指的是多进程交互。因为是多进程,所以也可以跨机器。但一般来说,MPI的开销会比openmp大一点。因为进程开销比线程大。所以在集群环境下,每个机器跑一个进程,MPI负责它们之间的通信;每个进程内部用openmp跑多线程。
MPI几个比较重要的概念:Group,Context,DataType,tag,以及比较常用的MPI_BCAST, MPI_REDUCE
FOSTER’S Design Methodology
很神棍的东西。基本上是partition、communication、agglomeration、mapping四个步骤,来设计一个并行程序。其中partition分为数据和计算的partition两种。
partition有几个设计原则很有意思:
- 任务数比单机核数至少10倍;
- 尽量减少重复存储数据和重复计算;
- 每个任务尽可能差不多大小
- 任务数和问题的规模是成单调关系。
communication原则:
- 每个任务的communication应当差不多;
- 最好只和一小部分邻居通讯
- 任务之间的通讯可以并行化
- 任务可以并行执行计算
Agglomeration,可以提高性能,维持可扩展性,简化编程,所以一般一个处理器一个聚合后的task
- 注意数据的locality
- 如果用一部分数据的拷贝,来减少通讯,注意多出来的计算需要能够和减少的通讯match
- 数据的拷贝不能影响可扩展性
- 多任务之间通讯计算的均衡,balance
- 任务的数量和问题规模、系统有关
- 代码的修改和聚合的好处之间应该有一个tradeoff
mapping是把任务分到具体的处理器上,分为动态和静态两种。
其实这部分在MPI_REDUCE等接口里,细节被cover掉了
4. 测试内存带宽
基础算法
1 | void test(int elems, int stride) { |
指令级并行( instruction level parallelism )
优化之前,我们需要知道现有的机器能支持的特性。其中非常重要的一条就是指令级并行。有下面三种:
- 超标量计算机。一次性可以执行多个指令。保证并行执行这些指令没有依赖关系。
- 超流水,流水线的级别变多。
- 向量计算机。指令是一条的,但是指令操作的数据有多个。也就是说一条指令计算多组数据。
一般来说,这三种方式都有。即一台计算机会同时又超标量、流水和向量三种。所以可以针对这些做一些优化。
循环展开
勿用多说,可以防止流水线被打断。实际上编译器会帮忙干这件事?
减少依赖
上面的基础做法中,result的值每一轮被计算,都要依赖上一轮的值。所以不能利用超标量。所以一种优化方式就是把加法拆开,如下所示。1
2
3
4
5
6
7
8
9
10int n = x.size();
for (int i=0; i<n; i+=8)
{
sum1 += x[i] + x[i+1];
sum2 += x[i+2] + x[i+3];
sum3 += x[i+4] + x[i+5];
sum4 += x[i+6] + x[i+7];
}
sum = sum1 + sum2 + sum3 + sum4;
这样sum1、sum2、sum3、sum4四个加法可以同时进行。
向量
16Bytes的向量1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
typedef int data_t;
typedef data_t vec_t __attribute__((vector_size(VBYTES)));
typedef union {
vec_t v;
data_t d[VSIZE];
} pack_t;
// header
while (((long) data) % VBYTES && cnt ) {
result = result + *data++;
cnt--;
}
while (cnt >= VSIZE) {
vec_t chunk = *((vec_t *) data);
accum = accum + chunk;
data += VSIZE;
cnt -= VSIZE;
}
// tail
while ( cnt ) {
result = result + *data++;
cnt--;
}
多线程
在此基础上,包一个多线程的壳就好了。pthread、openmp都可以
5. MapReduce和Hadoop
机器的平均故障时间(MTBF),大概在1w-100w小时这个量级。然而,现代集群有上万台机器,所有机器不出错的,MTBF,即使单机达到1M小时,系统也只有100小时。如果单机的MTBF为10w小时,系统的MTBF不到24小时。而一些计算任务很有可能算好几天。所以一出错就重头开始,不是一个很好的策略。
现代集群很多采取廉价机器,故障概率更大;而且对系统的弹性要求更高,能够动态增删节点。同时最好能支持多任务,并且能够有优先级调度。
所以google做了一套大数据系统,内部使用,并且催生了GFS,MapReduce等著名的论文;而开源社区把这些想法都实现了一遍,成就了hadoop。
- GFS — HDFS
- MapReduce —- java Implementation
- Scheduler —- Yarn
- Chubby —- ZooKeeper
- BigTable —- HBase
MPI 模型缺点
- 一开始知道问题规模,系统规模。
- 静态划分数据集。
我们可以从openmp的动态调度获得启发。每次只做一小部分任务;如果有处理器空闲,则分配任务给它。一直保持处理器在工作即可。
MapReduce 原型
Map: string -> [ {key: value} ] Reduce: key, [value] -> value
如kmeans1
2
3
4
5
6
7
8void map(point p):
for each mean in K means
find the closet mean M to this point
emit_intermediate (index of M, p)
void reduce(index of cluster i, list of points lp):
calculate the new mean M’ for points in lp
emit(M’)
6. Spark为代表的内存计算
MapReduce 最大的缺点就是无状态的,做完了一轮就什么都么有剩下。所以有时候需要迭代多次,如k-means,pageRank,就需要把中间结果写到磁盘上去;下一轮迭代再读出来。
内存计算是可行的,因为内存越来越大,而问题的规模有一定的上届。比如社交网络就是在10TB的量级。比较典型的内存计算应用:
- 分布式共享内存
- 分布式key-value store(Piccolo,RAMCloud,Redis)。其中RAMCloud用了一种buffered logging的技术来保证容错。就是在本地内存记log,然后在远程备份这些log和hashtable,然后刷磁盘。
但是log和backup太慢,一般是10-100倍的时间消耗。解决方案就是spark里面的RDD(Resilient Distributed Datasets)。有如下特点
- 由数据集合组成,而非单个数据
- 只能有特定的操作,如map,filter,join等。
- 不可改变,如果想改变,必须新建一个RDD
因为不可改变,所以每个RDD都是一个点,由一个或多个RDD生成一个新的RDD,然后我们就有了一个RDD的生成图。我们只需要记住这些操作即可,如果有错误发生,重新走一遍这些操作就可以得到原来的RDD了。
1 | messages = textFile(...).filter(_.contains(“error”)) |
上面代码会生成3个RDD,从HDFS读一个RDD, filter之后一个RDD,map之后一个RDD。
Spark 接口
两种接口:
- transformation,创建新的RDD,如map,filter,groupBy,sort,distinct,sample,reduceByKey等操作;
- reduce,从一个RDD获得单个数值,如reduce,count,collect,first,foreach等等。
Spark实现
比较有特点的是lazy evaluation,即一般的transformation不会触发计算,只有最后的reuce会触发整个DAG上的RDD的计算。
另外就是数据划分,以pageRank为例:1
2
3
4
5
6
7
8
9links = // RDD of (url, neighbors) pairs
ranks = // RDD of (url, rank) pairs
for (i <- 1 to iterations){
ranks = links.join(ranks).flatMap{
(url, (links, rank)) =>
links.map(dest => (dest, rank/links.size))
}.reduceByKey(_ + _)
}
因为每一轮links和ranks都会做一个join,所以partition的时候会尽可能把相同url的links和ranks放在同一个机器上。而且有一个函数叫PartionBy,专门来定义如何partition。
Spark的persist,指的是一个RDD应该怎么放。分为好几级。如Memory Only,只会存在内存中,如果不够大了,一些partition就会扔掉,等用到的时候重新计算。如果是Memory_And_Disk, 则在存不下的时候存到硬盘上;最极端的如DIS_ONLY,只存硬盘。
限制就是如果稍微改RDD中一个小数据,就需要复制一个新的RDD。如BFS就是一个很好的例子。
7. 流计算
之前所说的mapreduce 或者 RDD都可以说是批处理。batch。
但有些场景,比如满足量特别大,数据产生速度特别快,就不适应了。
流计算的模型可以用公式$F(X+\Delta X) = F(X)$ op $H(\Delta X)$。比如twitter分析,统计每个url被某个状态引用的次数。来了一个新的状态,不需要重新计算所有,只需要在原来的基础上加上一些值就可以了。
流计算的要求是:实时性;容错性和可编程性。第一点是流计算区别之前两个framework的特点。
一种naive的实现方式:Worker+Queue
队列是生成者向消费者发送的消息队列。Send语句用到了java的Future特性,即是异步通信。得到需要知道Send返回结果的时候,才会block。
- 全局有Producer和Customer两种角色。
- Producer产生消息,发送到队列里;队列分配消息到对应的Customer上;
- Customer再对数据库进行相应的操作。
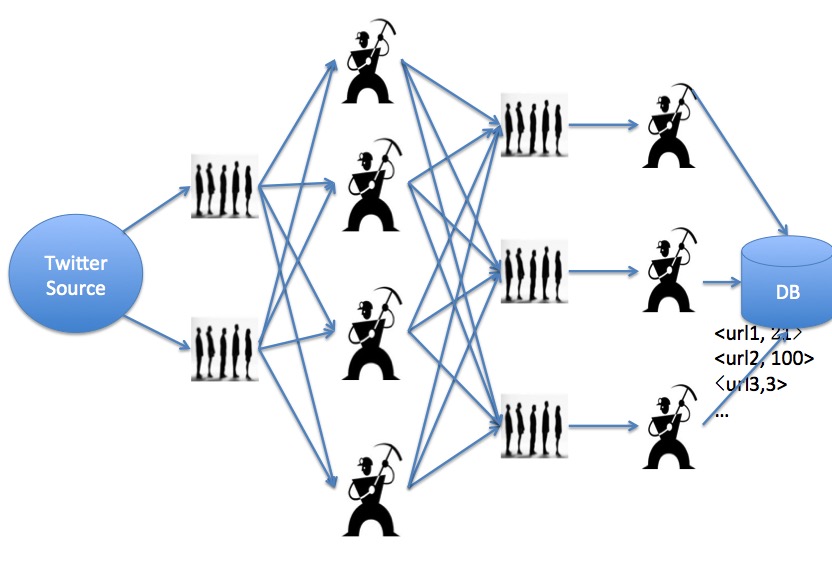
问题就是在可扩展性、容错方面很差,代码估计也很难写。可能是因为这个queue实现起来太复杂了。
流计算框架1:S4 - Simple Scalable Streaming System
S4支持有限的容错,用的是backup,原机器挂了就挂了,状态全部丢失,用backup代替。也不支持动态增删节点。
模型中重要的概念有PE(processing Element)和event,PE负责计算,彼此之间通过event交换信息,而不能直接访问数据。S4的框架帮我们做message的路由,需要我们自己实现PE和event。内部数据也都是(key, attribute)这样的形式。下图是个很好的例子
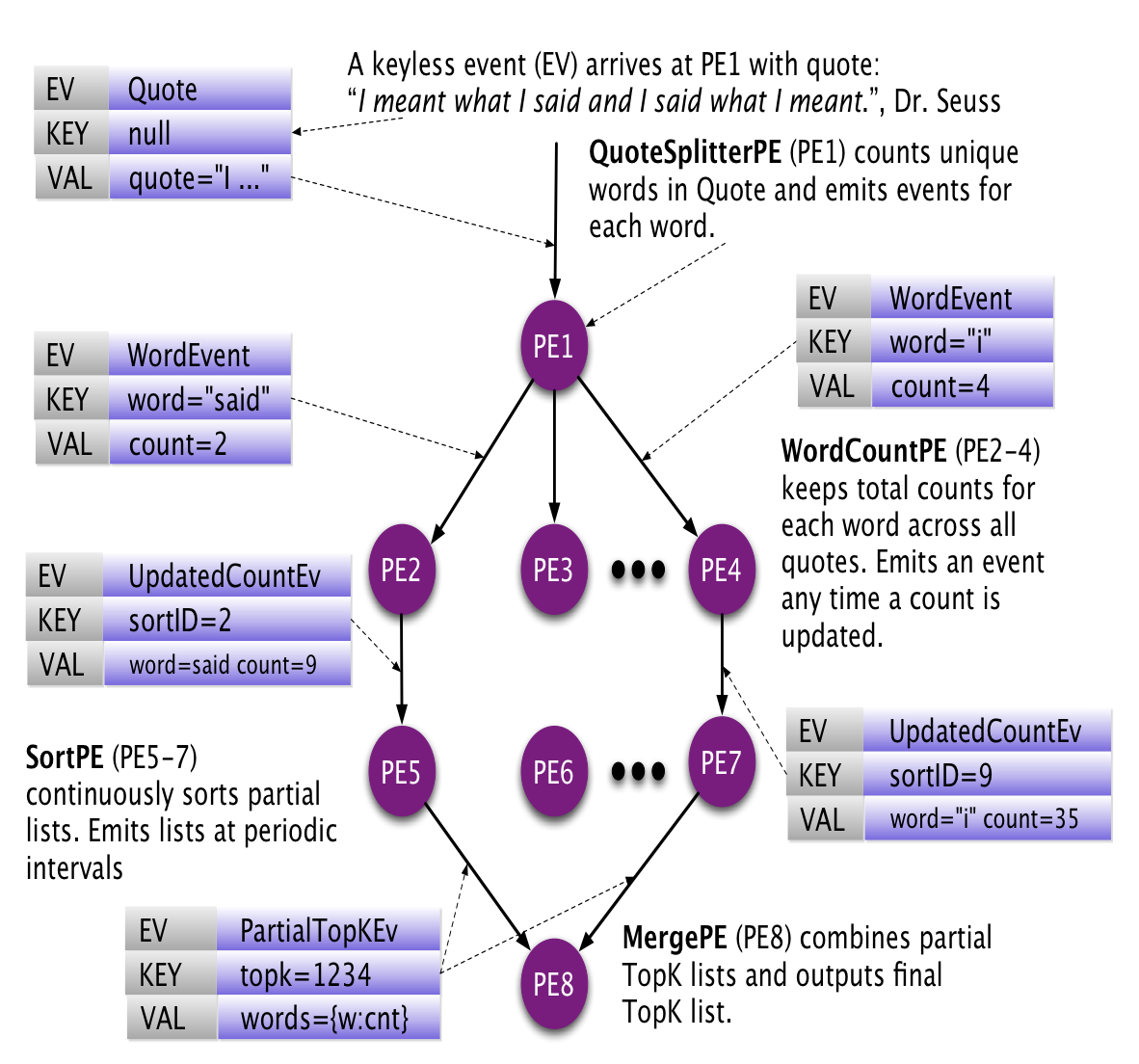
这幅图说明什么意思呢?开始的时候进来一句话,分词,然后根据单词作为key,分到不同的WordCountPE上。 注意,这里用单词作为key,确保同一个单词进入同一个PE。 然后在WordCountPE上,将单词的数量进行累加,然后把结果发送到SortPE上。注意,这里的key是一个sortID,即每个WordCountPE生成的结果都会发送到同一个SortPE 然后SortPE根据现有的数量状态,把结果发送到MergePE上。
我们可以很轻松地想象出代码怎么写,虽然我没用过S4。关键是SortPE上维持一个定长的数列,每进来一个新的{word, count}对,对比看看有没有当前的队列里最小的数值大,有的话,将最后一个扔出去,插进新的来。所以SortPE能保证自己存有最新的排名最靠前的word的信息;而WordCountPE能保证自己有自己存储的word的count信息。所有PE的状态都是对的。
一个key对应一个PE,如果一个新的单词出现了,会有一个新的PE随之创建 所以PE的垃圾回收是一个问题,而且很耗内存。
另外一种流计算框架:Storm
Storm里面重要的两个概念就是spout和bolts,比喻很形象,创建数据的都是spout,中间执行都是bolts。bolts可以执行各种操作,由用户来实现。
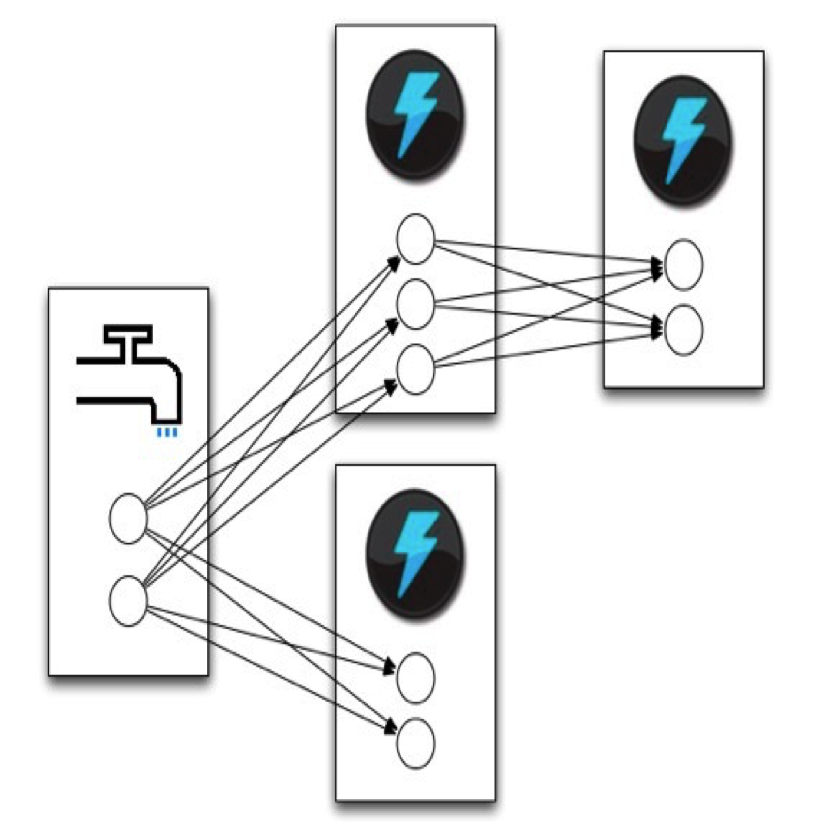
有了bolts,怎么让他们连起来呢?这就有了grouping的概念,Group是把bolts跟bolts连起来的操作。连起来之后可以保证前面blot/spout的输出能到达后面的blot。
有趣的是storm支持多种不同的容错:最多一次;恰好一次;至少一次;最多一次天然支持;我们来看至少一次怎么支持。
当spout发送一组数据的时候有一个全局的message id,当blot发送消息的时候,把output和input联系起来;当bolt完成计算,对input返回一个ack/fail。具体方式是:
- spout有个全局的id,sid,发出去的时候就产生了,然后记录到全局中:[ sid: sid ]
- bolt收到,根据input产生输出,形成一个新的tid,把所有input的sid和新产生的tid发到下一个bolt;同时在全局的sid中,sid对应的数值与tid做一个异或的操作。
- bolt确认自己所有的操作都完了,把input的sid(也可能是tid)与全局做一个异或。
纵观上面的算法,如果一个bolt,成功收到,并成功执行,会对输入的input的tid,做两次异或,结果等于0.所以只有最终全局变量sid等于0。这样就能确保执行失败会被发现。
恰好一次老师没有细说,估计比较复杂。
总体来说storm还是比S4复杂。(其实到现在还是没明白storm怎么写代码,但是S4可以想象)。但现在storm是apache的顶级项目,社区很活跃,被twitter使用。而S4稍微差一点,也是apache的项目。