Speedup RW-conflict tracking in PostgreSQL
Links
Introduction
PostgreSQL needs to track read-write conflicts (rw-conflict) among transactions executed concurrently at runtime. It uses a linked-list in the shared memory to record all conflicts of each transaction. Some benchmarks reproted that conflict-tracking took up a lot of CPU time at high concurrency levels. Using a faster data structure may help to speedup conflict-tracking.
Benchmarks
Current PostgreSQL benchmark tool pgbench can’t be used for serilizable transactions, because the program would exit if there is a transaction aborted by serilizable detecting. Thus I developed a new benchmarks to compare performance. It is a benchmark framework developed by GO and can be extended with new benchmarks easily. Now there are three benchmarks: ssibench, simple ssibench and tpcb. You can get more information in the github. The framework can also be used by other projects related to PG serilizable transactions in future.
Alternative data structures: hash table & skip list
We chose hash table and skip list to replace linked list to record conflicts, because the time complexities for searching of hash table and skip list are O(1) and O(logN) respectively.
However, after implementation we found these two data structures could not improve the performance for the reasons below:
The length of conflict list is not as long as we expected. In all benchmarks, 50% lists are shorter than 10, and all lists are shorter than 40. In this case, conflict tracking consumes less than 2% CPU time.
There are three basic functions maintaining conflicts information:
1 | /* Checking if a transaction is in the conflict list of another transaction */ |
Take skip list for example, it can speedup the function RWConflictExists, because searching complexity of skip list is O(logN). However, it makes SetRWConflict slower, because the inserting complexity of skip list is O(logN) while the inserting complexity of linked list is O(1).
Hash table has the same problem. Even its time complexities of searching, inserting and removing are both O(1), constant factors are much bigger than the linked list.
In a summary, hash table and skip list couldn’t improve the performance. Actually, I don’t think other common data structure (e.g. tree) can help. If one data structure can speedup the function RWConflictExists, it would make the other two functions slower. It’s my fault that I didn’t realize this consequence when writing the proposal. But the experience could be helpful for other developers.
Reduce contention on the global lock
There are many global locks used in PostgreSQL serilizable transaction model. I found waiting for locks took up much more time than conflict tracking when I profile the performance. SerializableFinishedListLock is one of locks which caused a lot of contention.
In PostgreSQL, a transaction can cause another transaction being aborted even when it is finished. Thus transactions can’t be released immediately whey they are finished. There is a list called FinishedSerializableTransactions maintaining these transactions. The SerializableFinishedListLock is used to protect this list.
The function ClearOldPredicateLocks is used to release finished transactions, the pseudo code is as below:
1 | lock(SerializableFinishedListLock) |
The function ReleaseOneSerializableXact takes up most time of ClearOldPredicateLocks. Actually, it doesn’t need the protection of SerializableFinishedListLock. Thus we can move it out the critical path so that there will be less contention on the lock. Here is the new pseudo code:
1 | vector releasedTx; |
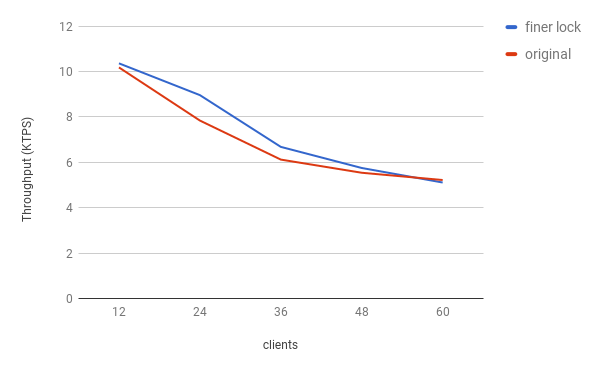
Here is the result. I used simple ssibench as the benchmark. The red line indicates the performance of the original code, while the blue line indicates the performance of the new code. When the number of clients is small, lock contention is not the bottleneck so there is no much difference. When there are 24 or 36 clients, the new version is at most 14% faster. When there are too many clients, contentions on a finer lock, i.e. predicate lock, become the new bottleneck. Thus the performances of two versions are similiar again.
Summary
In this project:
1) I provide a systematic benchmark for PostgreSQL. The existing benchmark tool pgbench can’t be used for serializable transactions.
2) I tried to use a faster data structure to speedup conflict-tracking but found that other parts would be slower and the performance couldn’t be improved.
3) I provided a new patch to reduce contentions on the global lock, which can be 14% faster than the old version in some cases.