tpc-c
TPCC是一个测试数据库性能的benchmark,是一个标准。很多transaction相关的论文都是以这个标准来评测性能的。
介绍
TPCC模拟了一种生活中电商的场景。这是一个全国性的电商,有若干个仓库中心,warehouse,每个仓库负责10个区域,distinct,每个区域有3000个客户,customer。规模的变化就在于仓库的数量变化。整个公司有100000个货物(items),每个仓库单独的库存(stocks)。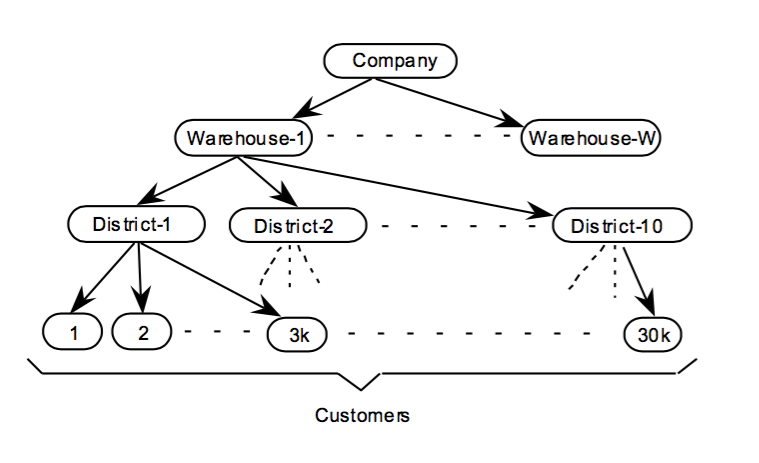
Customer做的事情就是下新的订单,或者查询之前的订单。订单由若干个(平均10个)order line构成,每一个line表示该订单里的一个货物。正常情况下,货物由customer所在地所属的仓库中心提供,但是也有1%的概率由远程仓库提供。
同时从公司的角度来说还有付款、推迟订单、测试货存的操作。
一般这个benchmark都是架在数据库上的。所以会有一些数据库的表。表的结构如下: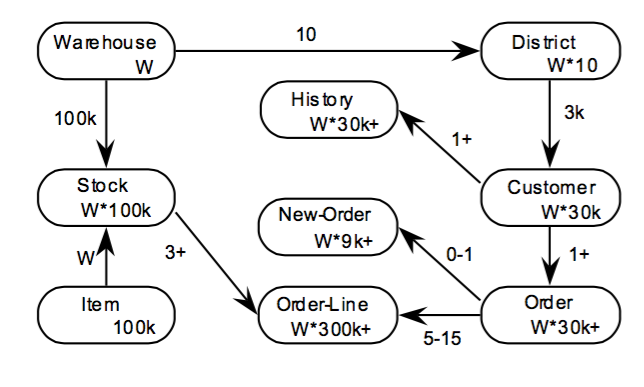
New Order
数据产生:
- 对于任意一个给定的终端,warehouse是固定的。W_ID
- distinct 是从warehouse中随机取一个。[1..10]。然后从该区域中随机取一个customer,[1..3000]
- 随机选出需要下单的商品的数量,5-15,并随机产生每个item具体的数量。这些都是由终端产生的。
- 1%的new order操作会失败。所以需要随机一个rbk的数[1..100],为1的话就表示要失败。
- 对于第3步选出来的商品数量:
5.1 随机选出一个商品id,如果这是最后一个要买的商品且rbk值为1,设置该商品的数量为unused number,导致一个not found的结果。
5.2 选取一个供货仓库。99%由本地仓库,即W_ID,1%概率是远程仓库,也可以产生一个随机[1..100]的数。
5.3 随机产生一个[1..10]的数量 - 根据系统当前时间产生日期
- 设置order-line,根据是否本地仓库供货,设置为home或者remote