dryad
Dryad是微软推出的一个分布式计算框架,类似于MapReduce。但影响力远不如MapReduce。跟MapReduce的区别是编程接口更复杂/灵活。
1.OverView
Dryad把所有的任务抽象成一个DAG,每个节点表示一个程序,每条边表示一个数据传输。数据传输可以是管道、网络甚至是共享内存。因为数据传输是一个统一的抽象概念,所以需要用户自己实现数据的序列化和反序列化。
分析流程可以通过一个SQL的例子来看。1
2
3
4
5
6
7
8
9
10
11select distinct p.objID
from photoObjAll p
join neighbors n -- call this join “X” on p.objID = n.objID
and n.objID < n.neighborObjID
and p.mode = 1
join photoObjAll l -- call this join “Y” on l.objid = n.neighborObjID
and l.mode = 1
and abs((p.u-p.g)-(l.u-l.g))<0.05
and abs((p.g-p.r)-(l.g-l.r))<0.05
and abs((p.r-p.i)-(l.r-l.i))<0.05
and abs((p.i-p.z)-(l.i-l.z))<0.05
这个例子就是求一个恒星满足某个条件的邻居。第一个join是找到所有的邻居,第二个join是判断是否满足条件。
然后我们看Dryad如何实现这个查询的。如下图所示,U和N表示object和neighbor。开始的时候,U和N按照objectid被分成N份,X节点表示做了一次join。D节点表示把X产生的数据,按照neighor_id进行分类,传给M。至于为啥是4*个,因为每个机器有四个核希望能够用起4个管道。M中把接受到的数据合并起来送给S,S中进行一个快排,传给Y。Y再把U和S的数据做一个join,得到结果。所有的Y把结果发送给H,H进行统一归并。
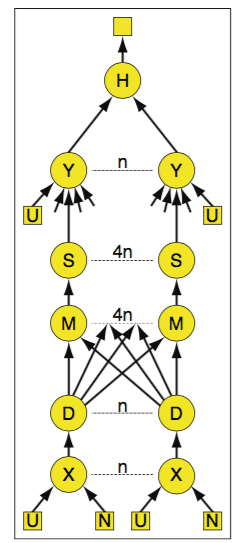
2. Dryad图
G =
Dryad提供了一套构建图的语言;点很简单,直接加进去就好了;边稍微有点复杂,因为有多种加边的方式,如下图所示: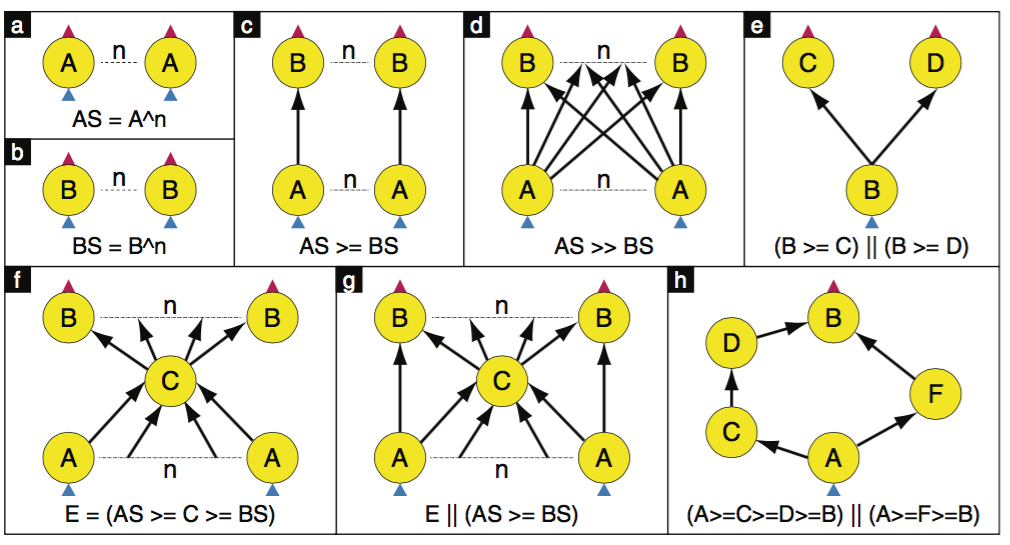
下面这张代码就是前面那个SQL的实现。重点观察一下图中边的构建即可。
1 | GraphBuilder XSet = moduleX^N; |