lock-free
本文是一个翻译,是一个总结,原链接
what is it
首先,lock free的概念不仅仅是代码中不使用mutex之类的东西。参考下图,如果一路yes,说明是lock free,如果前面条件不满足,说明也不是lock free。
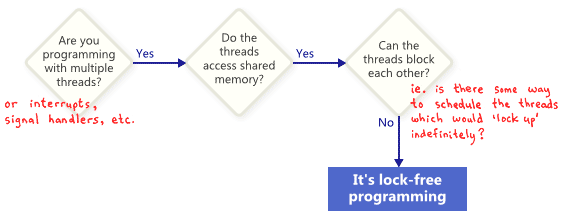
lock free就是说,不会用锁;也不会因为潜在的线程调度导致bug。比如两个线程,同时执行下面代码,其中,x是共享变量:
while(x==0)
x = 1-x;
有一种可能性,是两个线程都不会跳出循环;(A 线程读x=0,B线程读x=0;A线程执行x=1-x,得到1,B线程执行x=1-x,得到0,回到开始的位置了。)所以这不是lock free
多处理器编程艺术里面给了一个定义:”In an infinite execution, infinitely often some method call finishes.”就是说,只要有程序持续调用函数,已经完成的函数调用数目一直在增加。
一个重要的结果就是,如果一个lock free的程序某一个线程被挂起来,其他所有的程序都不会被阻塞。因此不需要设置time out之类的东西了。
lock free 的技术手段
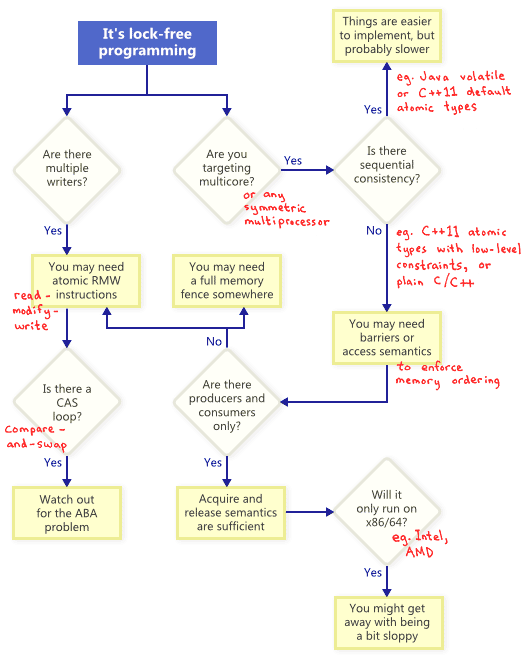
常规的手段显然是不行的,因此需要很多新的手段,按照这张图我们一个个分析。
Atomic Read-Modify-Write Operations
原子操作,指的是处理器执行指令,没有一个线程可以看到执行的中间状态。实际上,现代处理器,很多操作都是原子的,比如read/write memory的操作。
Read-Modify-Write更进一层,读内存-修改-写内存,三个操作集成到一个原子操作里;实际上就是一个transaction。现有的win32 里的 _InterlockedIncrement 指令,iOS里的 OSAtomicAdd32 指令,或者说,C++11里的std::atomic
从流程图中我们可以看出,即使是单线程程序,RMW也是有用的,因为它实现了一个transaction,避免操作出现一半中断了,带来错误的后果。
Compare And Swap
可能最常见的RMW指令就是CAS,如果相同就更换。比如win32的指令就是_InterlockedCompareExchange,我们可以用CAS实现一个lock free队列:
void LockFreeQueue::push(Node* newHead)
{
for (;;)
{
// Copy a shared variable (m_Head) to a local.
Node* oldHead = m_Head;
// Do some speculative work, not yet visible to other threads.
newHead->next = oldHead;
// Next, attempt to publish our changes to the shared variable.
// If the shared variable hasn't changed, the CAS succeeds and we return.
// Otherwise, repeat.
if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead)
return;
}
}
这样即使有一个thread test失败,说明另外一个线程更改成功;所以这是一个lock free。_所有用到CAS指令的,需要小心ABA问题_
Sequential Consistency
定义:所有线程有着相同的内存操作顺序,这种顺序与源代码相同。这样防止了处理器或者编译器的reorder。
在C++11中可以定义atomic对象,这样所有的操作都是顺序一致性的。Java中可以用valatile关键字。
std::atomic<int> X(0), Y(0);
int r1, r2;
void thread1()
{
X.store(1);
r1 = Y.load();
}
void thread2()
{
Y.store(1);
r2 = X.load();
}
这样,不会出现X,Y均为0的现象;因为不会出现reorder。一般来说,编译器会加上memory fences或者使用RMW指令。相比于直接定义memory order,这种做法会有些额外的开销。
Memory Ordering
如果环境不支持Sequential Consistency,需要自己确定,防止memory reorder。现有的技术条件下,方法有三:
- 轻量级的sync或者fence指令
- 完全的内存fence指令
- 有着获取或者释放(Acquire and Release)的内存指令
Acquire指令防止自己之后的指令跑到自己前面,Release指令防止之前的指令跑到自己后面。这种指令尤其在生产者消费者模型中很合适。
Different Processors Have Different Memory Models
比如PowerPC和ARM的芯片可能会更改有着内存相关性的指令顺序,而x86就不会。因此前者更复杂。幸好有着C++11这样的快平台模板,掩盖了底层的细节。但我认为,即使这样,程序员也应该意识到各个系统的差别。比如,x86每一个读内存都有个release指令;写内存都有一个acquire指令。