CC(1) "1. The Problem"
接下里我会写一个系列的博客,介绍concurrency control的相关知识。主要是本人看《concurrency control》这本书的读书笔记。会按照个人的理解,进行浓缩或者扩展。
1.1 Trasaction
搞过数据库的人都接触过transaction(事务)这个概念,具体的定义就是”一组操作的集合“,比如银行中存100块的transaction就是,读原来的存款额度,加上100,写入数据库。包括一个读操作和一个写操作,可以称之为一个transaction。这是非常简单的,实际上transaction可以非常复杂。
对于transaction一个基本的要求就是automic(原子性),这里有着两层的含义:
- 不同transaction获取共享的数据,彼此之间没有任何交互。一个transaction要么看到另外一个transaction写完的数据;要么看到它未开始的数据。比如一个transaction T1写了A,B两个数据,另外一个transaction T2要么看到T1写之前;要么看到T2全部写完。不能说T1写了A,但没有写B,T2读了此时的A和B。
- 一个transaction的结果要么永久有效,要么毫无影响。比如一个transaction对两个数据进行写操作,要么两个都写了,然后永久性保存;要么一个都没写成功。不能出现一个成功一个不成功的现象。
然后一个transaction会有三个基本操作:
- start,表示这个transaction开始了;
- commit,提交,说明这个transaction结束了,如果返回成功;说明结果已经得到永久性保存。
- abort,取消,取消之前所有的操作,对于整个系统来说,这个transaction相当于没有发生过。
以及transaction有着两种状态:已经start,还没有commit或者abort,称之为active;active,或者abort,称之为uncommited。
那么,不同的transaction之间是怎么交互呢。一般来说,每个transaction都是自洽的,即自己管理自己;所以不同的transaction通过写共享的数据,来进行交互。也就是说,transaction之间不会直接进行通讯,只是通过共有的数据来传达信息。
1.2 Recoverablity
这里的recoverablity和把数据存到永久性磁盘,是不一样的。
具体定义为:1. 一个数据库必须包括所有已经commit的数据;2.不包括任何没有commit的数据。前者是很好实现的,因为直接将所有transaction的操作写到数据库里就行了;所以这个问题的主要症结在于abort。比如一个transaction写了数据A,然后abort,那么数据库必须清除掉已经写了的数据A。
当一个transaction abort的时候,必须考虑两个方面,第一是数据,所有该transaction的写过的数据必须恢复;第二是其他transaction,所有受到影响的transaction(读了该transaction写了的数据)必须也要abort。如果一个transaction abort,产生连锁反应,造成一系列的abort,这种现象称之为”cascading abort”。
而且,更严重的问题是,此时,这个受到影响的transaction已经commit了,不能被abort,系统出现了矛盾。比如下面这个例子:
Write1(x, 2); Read2(x); Write2(y, 3); Commit2;
这样破坏了recoverability的定义。所以我们需要加一个限制条件:所有在自己读取数据上刚刚进行写操作的transcation,都commit之后,自己才能commit。这样就避免了刚才的问题。
Terminal IO
另外一个比较有意思的话题是关于terminal,程序员通过terminal与数据库交互,一个transaction中间输出结果怎么办。如果不等commit,就输出;这就违反上面的条件。如果等待commit之后才输出,如果中间需要输入怎么办。
所以,这里需要程序员自己很小心。不管是哪一种方式,系统提供了一套接口,满足一系列条件;程序员需要小心翼翼地进行操作。举个例子,如果中途输出结果,在系统没有确定commit之前,程序员不能依据这个结果开启下一个transaction。
Cascading Aborts
(这个词不知道怎么翻译好,意译可以称为”连锁取消“),可以继续加一个限制:不读没有被commit的transaction写的数据。这个很简单,反正自己读的数据都是被commit过的,不会abort,也不用担心自己会被连累。
Strict Execution
按照之前的说法;如果一个transaction写了数据A,然后Abort,这时候需要restore数据A。但是忽略了这样一个现象:如果在T1写了数据A,abort之前,另外一个transaction写了怎么办。最简单的例子就是下面这个例子:
Write1(x, 1); Write2(y, 3); Write1(y, 1); Commit1; Read2(x); Abort2.
因为T2只记得自己写之前,y的数据,它并不记知道其他人在自己之后有没有写了。所以T2 restore的时候,只能放置自己记得数值。这样就有了错误。
故,需要再加一条限制,写操作必须等之前的写操作的transaction commit或者abort之后,才能进行写。这些条件加起来,就是所谓的strict execution。具体定义:一个transaction写完x之后,必须等到该transaction commit或者abort之后,其他的transaction才能继续读写。
(很明显,我们能想到的解决方案就是写的时候加锁。然而,需要提醒的是,锁不是根源,根源是为了确保recoverability,锁是一种解决方案)
1.3 Serializability
仅仅保持Recoverability是不可以的。一种现象是lost update: 比如两个transaction,都读了原始的数据,然后根据原始数据计算,然后写到数据库中。例如在银行存款中,原始是100块,一个transaction存了10000块,另外一个存了1000。理论上最终结果应该是11100,但是如果按照下面的顺序执行:1
2
3
4
5
6Read1(Accounts[13])
Read2(Accounts[13])
Write2(Accounts[13], $10100)
Commit2
Write1(Accounts[13], $1100)
Commit1
最终结果是1100。另外一个问题是PrintSum,性质是一样的。这里就不再举例。总而言之,所有的问题都是transaction交错执行造成的
如果说我们禁止transaction进行交互,Serializability能够得到保障;但是这样性能太差,也就没了concurrency的事情了。Serializability的定义是:多个transaction一起执行,结果和依次执行所有的transaction的结果是一样的。这里注意两点:1. 依次执行的意思是对所有transaction,任意排一个序列,然后一个一个执行,没有交替;2.是结果相同,过程不重要;只要有一个顺序执行的序列和交错执行的结果相同,就可以认为是serializability。
如上面的例子,将顺序调下,就可以得到一个serializable的执行:
1 | Read1(Accounts[13]) |
正如上文所说,多个transaction的顺序不一定,只要最终结果跟一个序列的结果一致就可以了。所以,如果user偏向于某种顺序,必须自己使用某些方法进行保证。
Serializability Limis
未必所有的系统的目标就是Serializability,甚至未必提供transaction的语言。
一个例子就是即使牺牲了Serializability,结果受到的影响很小,误差是可以接受的;如果性能得到极大的提高,那么也就无所谓了。
另外一种就对于无限循环的程序,不会终结,也就没有了serial的意义。每个程序内部可能有互斥区,最多只能有一个线程执行;用锁等方式进行实现。这也是另外一种形式的concurrency control。
1.4 Database System Model
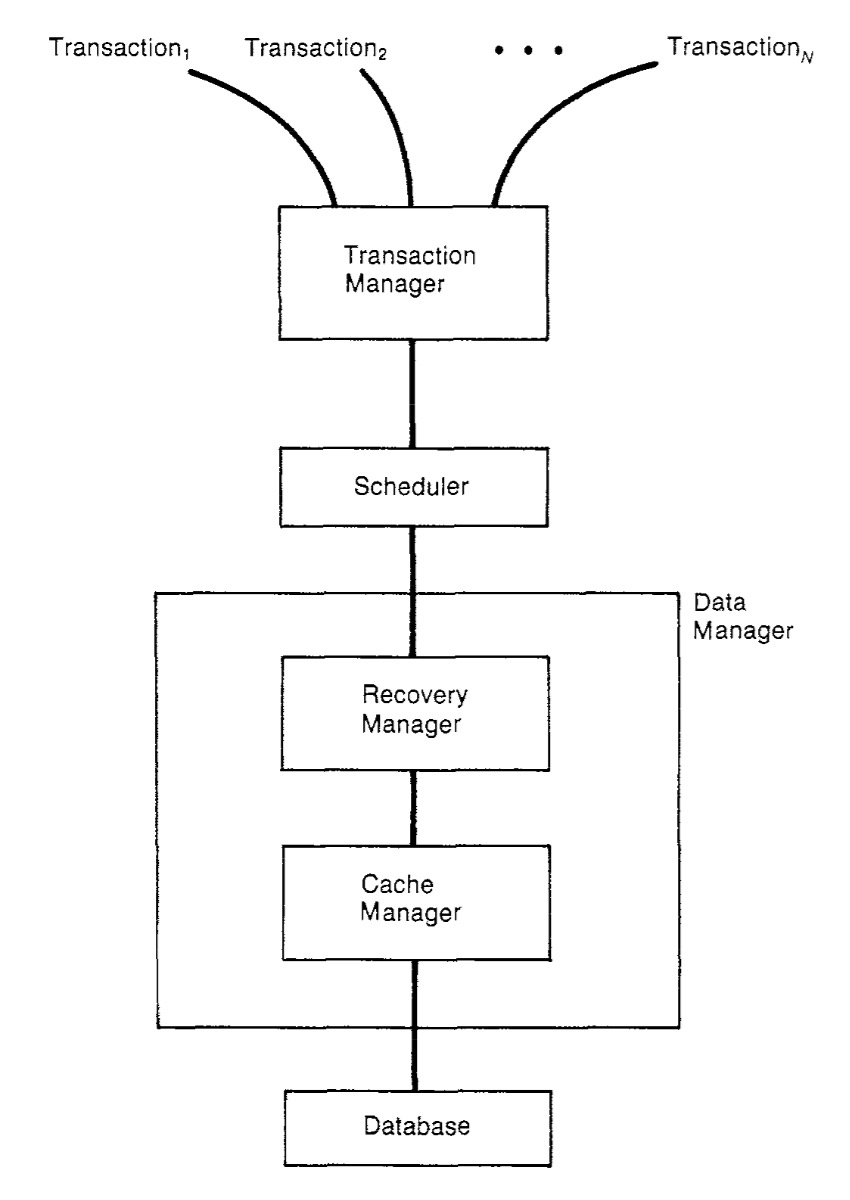
这里简单介绍一下数据库系统的模型。如下图所示,从上到下可以分为四个部分:
- Transaction manager,接受各个transaction的输入,制定顺序等;
- Scheduler,对每个transaction中不同的操作进行调度,使得满足serializability。
- Recovery manager, 负责管理transaction的commit和abort。会调用下层的Fetch/Flush接口。除此之外,RM还需要能够处理传统的system failure,跟以往意义上的Recoverability相近。
- Cache manager,直接操作于数据库。之所以这么做,是因为内存不足,只有部分数据会被缓存在内存里,所以称之为cache。cache manager实际上就是控制数据在内存和硬盘上的行为。向外提供Fetch和Flush的操作。
操作的顺序
需要说明的是,各个Manager执行各个操作的顺序是自己定的。比如Scheduler传递两个操作p和q,p在前,给了RM,RM却可以先执行q。为了避免这个问题,Scheduler需要等RM返回了p执行完毕的确认信息,再传递q。
分布式数据库结构
分布式环境下,每个单机上有一个独立的系统。彼此之间通过Transaction Manager进行交互。比如一个机器上没有某个数据x,关于x的操作会被转发到另外一个Transaction Manager上。