GFS
这学期上了康总的分布式系统的课程,每一节课学习一两篇分布式的论文。所以这里会有一个系列的文章,介绍这些论文,权当做一个复习资料。
1. GFS
GFS,BigTable和MapReduce,作为google的三驾马车,名声已经烂大街了。在现在所谓的大数据时代中,任何一个学计算机的人,如果不知道GFS,都不好意思出门了。
GFS全称是Google File System。早年google内部实现的一个分布式文件系统,用了之后感觉效果很好,于是乎在2003年发了一篇SOSP,距今已经十几年了。而google本身是1998才成立的,所以我们有理由相信,GFS是在google诞生初始就开始开发使用了。
在此之前,分布式文件系统的概念已经有了。然而在google的应用场景中,有了如下的条件:
- 机器出错是一个常态;因为机器的数目太多了。一台linux机器可以持续运行不出错的时间大概在1w到10w个小时之间;如果几千台机器一起运行,所有机器不出错的持续时间可能只有几个小时。
- 以往的文件系统处理的是大文件,都是在GB或者TB以上;所以对小文件的支持就很差。所以可能需要有一种可以调节的参数进行设计。
- 文件的append(在结尾处追加)是常态;而随机写很少。所以重点优化对象是append。
- 下层文件系统的设计和上层应用的设计是一起进行的。所以有些接口为了方便,跟传统的单机文件系统不太一样。比如文件系统支持原子的append操作,这样多个客户端直接不用上锁,可以直接调用接口。
当年(2003年之前)GFS已经布置起来了多个集群,其中大的有1k个机器,300TB的硬盘空间。(现在一台机器就已经几十个TB的存储空间了)
下面我们将详细介绍整个系统。
2. 系统设计
2.1 假设条件
- 使用了大量廉价机器,所以机器很容易坏。所以系统本身必须支持容错。
- 主要的对象是大文件,通常是GB这个量级。小文件的优化不作考虑。
- 读的操作有两种:大量顺序读和少量随机读;
- 写的操作主要是大量的append;少量的随机写也支持,但是性能不用重点考虑。
- 需要重点考虑多个client append的情况,提供良好的语义(也就是说client用起来方便)
- 要求高带宽,不要求低延迟;
2.2 接口
很像posix的文件接口,create, delete, open, close, read, write都支持。
此外支持snapshot和append。后者保证是一个院子操作。
2.3 构架
下面祭出了这张著名的构架图。有一个master节点和多个chunkserver,以及多个client相连。这些都是linux的用户态程序,直接调用的是操作系统的提供的文件接口。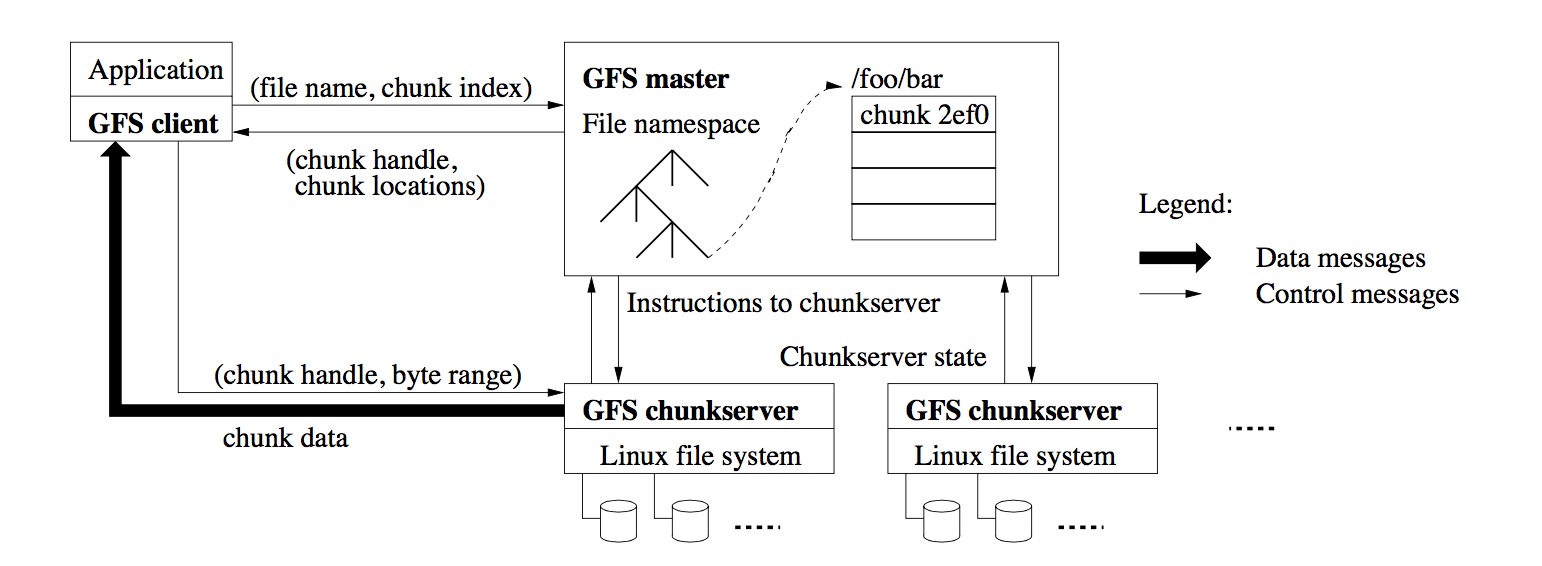
每个文件被切成一块一块的,每个chunk都是有一个独特的id,被当成普通文件,存在chunkserver上。master节点负责记录这些chunk的信息。比如一个文件被切成了多少块,每一块在哪个机器上。一般情况一下,一个chunk会有若干个副本,防止其中某一台机器挂掉了,文件不会丢失。
而client会通过API与系统交互,读写数据。API和master交换元数据,和chunkserver交换真正的文件数据。
2.4 master
master节点只有一个,这样可以大大简化系统的设计(当然也会有单点故障之类的问题)。所以为了防止瓶颈出现在master上,任何文件数据都是client和chunkserver自己直接交互的。master只负责提供元数据。
比如上图中,因为知道了chunk的大小,client可以计算出需要的数据的文件名和chunk编号,发送给master;master返回对应的chunk的地址;client再跟具体的chunkserver进行数据交互。
2.5 chunk size
该值设为64MB,因为大有下面几个好处:
- chunk少了,client访问master次数变少;
- client和chunkserver的访问次数变少,因为更多的请求可以在一个chunk里完成;
- 元数量变少,master的容量压力变小。
2.6 元数据
主要存了三种数据:1. 文件的命名空间,2. 文件到chunk的映射表,3. chunk的副本信息。都是存在内存中的,但是前两种需要log防止crash,甚至需要备份log到另外一台机器;chunk的信息由chunserver自己报告给master,有一个heartbeat信息。这部分信息不用存在磁盘上。
2.6.1 内存数据结构
其实关于内存的一个问题就是能不能放得下所有数据。每个chunk 64MB,占用的元数据不到64B,而同时大部分的chunk都是满的。所以1GB的内存,可以存储1PB的文件。
2.6.2 chunk的位置
正如前文所说,master开始并不存每个chunk到底存在哪个chunkserver上。它是向chunkserver请求heartbeat信息来获取。这样其实可以大大减少一致性等问题的复杂性,这样chunk的信息完全由chunkserver决定的。
2.6.3 Operation log
为了防止master节点的故障,需要对操作打log,并且存在不同机器的硬盘上。只有log被flush到硬盘上之后,才会给client发回成功信息,这样保证语义的正确性。
重启的时候,需要把log重新执行一遍;为了防止log太长,所以每隔一段时间需要做一个snapshot,把状态保存下来;在此基础上执行log,这样的log会少很多。
2.7 一致性模型
一致性的问题,在分布式系统里是一个基础问题。因为GFS的特殊结构:一个文件切分成多个chunk,每个chunk分成多个复本;而多个client可能同时操作同一个文件,所以一致性也分成两个问题:
- 多个chunk之间的一致性。是不是一致的。即不同的chunk最新状态是不是由同一个操作完成的。
- 同一个chunk多个复本,是不是一致的。
一致性分为三个级别:
- consistent,所有的client看到的数据是一致的;不管什么时候;可能不是最新的
- inconsistent, 两个client看到的数据不一样;
- defined,不仅仅是consistent,同时知道哪些数据是哪些操作写入的。所以,这是最强的一致性要求。
元数据修改由master完成,所以没有一致性的问题。主要是chunk。又分成几种情况:
- 连续写,肯定是defined;
- 并发写成功,是consistency的;但是因为一堆写混合,我们不知道一堆数据中,哪些操作写了哪些数据。因为有可能有重叠。
- 如果失败了,就是inconsistency了。因为不同chunk写的数据可能不一样了。
除了写,提供了append的接口。这里的append的意思是原子性地写一次。跟传统的计算offset不太一样。而append本身是可以定序的,定完序之后肯定是defined。
但是偶尔会出现一些错误(这个不太清楚为啥)对导致一定量的inconsistent,但是GFS本身有额外的方案可以解决这个问题。
3. 系统接口
3.1 租约系统
前面说过,需要保证chunk之间的一致性。GFS通过在副本中选一个leader 的方式,由leader定序,来确保一致性。选leader就是通过分配一个lease。这一期间都是该副本来控制数据流。如下图所示。值得注意的是,3中数据本身的传输没有必要时顺序的。也就是说可以同时做。只是其他步骤按顺序来即可。
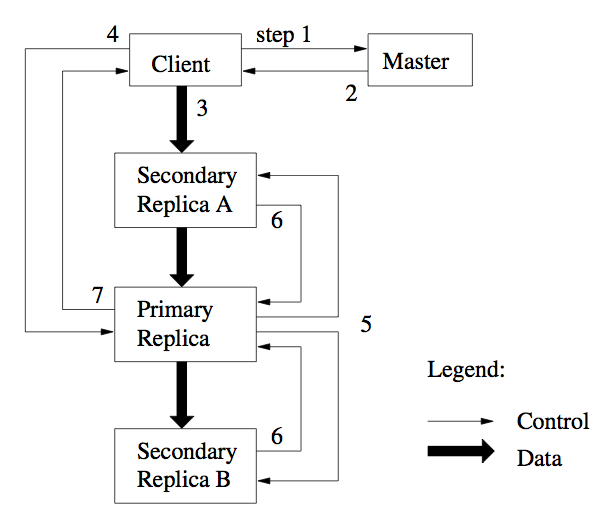
3.2 数据流
在数据流中,是一个链状的顺序。比如S1要传到S2 3 4,会选择一条最近的路组成一个链去传。远近根据ip判断。因为网络很简单。
3.3 append
append 操作只需注意,由primary chunk server控制;如果append之后,超过block 的size,64MB,则把该块填满,告诉客户端需要再尝试一下。因为系统会产生一个新的block。所以强制要求append的数据不能超过四分之一的block大小。
3.4 snapshot
就是创建副本。用的copy on write的技术。收到snapshot请求,收回所有的lease,并复制元数据。然后完成。元数据指向的各个块和原来的文件是一样的。实际上数据只有一份。
等有新的写操作进来,会要求对应的chunk server创建一个新的块,然后再把租约给它。完成。
4. Master的操作
4.1 命名空间
这可能是最重要的一点了。为了简单,没有目录树和link的概念。实际上就是一个全路径到文件的映射。用前缀压缩来高效查找。
每个文件有一个读写锁。所以每次master操作之前都会获得锁。且会获得所有的父节点的锁。比如/d1/d2/d3,会依次获得d1 d1/d2 d1/d2/d3的锁。
这样效率比较低,但是很方便,防止了在操作子目录的时候父节点被删了之类诡异的现象。
4.2 副本布置
考虑两点: 数据可靠性,最大利用带宽。分布是跨机架的,为了可靠。读取的时候可以利用多个机架的带宽。虽然这样在写的时候会有跨机架的通讯。他们觉得也ok。
4.3 块副本创建
block的创建原因有:create、重新复制和负载均衡。
放置策略:硬盘使用均衡;限制近期创建的数量;机架之间分布。
重新复制的原因是因为可用副本少了。可能是硬盘损坏、reconfigure等原因。
4.4 垃圾回收
垃圾回收是lazy的,不立刻回收。
机制就是当删除的时候,换了一个隐藏时间戳的名字。后台会阶段性地扫描,回收资源。在此之前,可以用新名字访问;也可以通过重命名恢复。
对于block,chunkserver报告它的chunk信息,master会回复哪些块失效了。chunkserver会删除这些块。
4.5 过期副本检测
对于每个块,master保留一个版本号。当有新lease的时候,版本号会增加,master告诉所有的chunkserver。如果有人临时挂了,版本号没有增加,之后会检测出来。
5. 容错
5.1 高可用性
快速恢复:不管如何关闭的,都可以在几秒内重启。所以大部分情况只是超时。
块复制: 即使某些服务器或硬盘完全坏了,可以用副本。
主节点备份: log和checkpoint需要备份。shadow master提供只读服务,会有滞后。
5.2 数据完整性
通过checksum来校验。
5.3 诊断工具
实际上就是记日志,然后开发很多分析日志的工具。貌似大家现在都是这么搞的。还有专门的日志分析公司。
后面的性能评测就不说了,自己看原文即可。