算法(上)
1. 基础知识
1.1 函数增长
Θ: 渐进界,存在常数c1, c2,0 ≤ c1g(n) ≤ f(n) ≤ c2g(n)
O: 渐进上界,0 ≤ f(n) ≤ cg(n)
Ω: 渐进下界 0 ≤ cg(n) ≤ f(n)
o: 非渐进紧致上界,对任意正常数c > 0,存在常数 n0>0,使对所有的n ≥ n0,有0≤f(n)<cg(n)
w: 非渐进紧致下界,类似上面。f(n) ∈ ω(g(n))当且仅当g(n) ∈ o(f(n))
函数间关系,满足传递性(所有)、自反性(Θ、O、Ω)、对此性(Θ)、转置对称。
有的函数之间无法有上面的关系比较。
特殊函数:
对数函数: ln(1+x)的泰勒展开形式,任何多项式都比对数增长的快,非渐进紧致上界的关系。
阶乘函数: n! = o(n^n); n! = w(2^n); lg(n!) = Θ(nlgn)
函数迭代的定义。
多重对数函数。所以注意和对数的k次方之间的区别。增长最慢的函数了。
1.2 分冶和递归
合并排序
1 | MERGE-SORT(A, p, r) |
这是典型的分冶策略,本质是递归。运行时间也可以用一个递归方程来解。
最大子数组问题
输出连续子向量的最大和(长度不定)
方法一:遍历所有的子串 O(n^3)1
2
3
4
5
6for i = [0, n)
for j = [i, n)
sum = 0
for k = [i, j]
sum += x[k]
maxsofar = max(maxsofar, sum)
过程中浪费了一些信息,实际上x[i..j]和x[i..j-1]只差了一个x[j],没有必要重新扫描算两遍。1
2
3
4
5
6maxsofar = 0
for i = [0, n)
sum = 0
for j = [i, n)
sum += x[j]
maxsofar = max(maxsofar, sum)
分冶算法,尽量等分,找出子部分最大子数组、同时找出跨划分节点的最大子数组。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15float maxsum3(l, u )
if( l > u ) return 0
if( l == u )
return max(0,x[l])
m = (l + u)/2
lmax = sum = 0
for ( i = m; i >=l; i-- )
sum += x[i]
lmax = max(lmax, sum)
rmax = sum = 0
for i = (m, u]
sum += x[i]
rmax = max(rmax, sum)
return max(lmax+rmax, maxsum3(l, m), maxsum3(m+1, u))
后面会给出说明,这个算法的复杂度为nlgn。
扫描算法:还有一种思路,如果我们已经解决了x[0..i-1]这个数组的问题,如何扩展到x[0..i]这个数组呢?想法很简单,要么x[0..i]直接使用之前的结果,即不包含第i个数;要么包含第i个数,最大子向量是一个数组的”尾巴“。1
2
3
4maxsofar = 0 maxendinghere = 0
for i = [0, n) /* invariant: maxendinghere and maxsofar for x[0..i-1]
maxendinghere = max( maxendinghere+x[i], 0 )
maxsofar = max( maxsofar, maxendinghere )
复杂度为O(n)
递归树来解决时间复杂度
求叶子节点个数、深度和每一层的复杂度。求个和即可。
空间中最近的点
naive的算法,两两求距离,n的平方的复杂度。
分冶算法,两个部分内部最小距离、跨区域的最小距离。有意思的是跨区域怎么算,如果还是两两算,依旧是n的平方复杂度,没有意义了。所以做法是,先找出左右两边的子区域内最小距离d。然后筛选出距离分界线d范围以内的点。
同时呢,对于每一个p,只考虑在y方向上距离d以内的点。同时我们可以证明出这些点的个数在7个以内。所以是o(n)。
递归式的解法
代换法
猜测某个界,然后用数学归纳法。可以和递归法配合着用。
需要注意的是确定边界条件。
递归树法
前面已经简单介绍过了。
主方法
形如:T(n) = aT(n/b)+ f(n)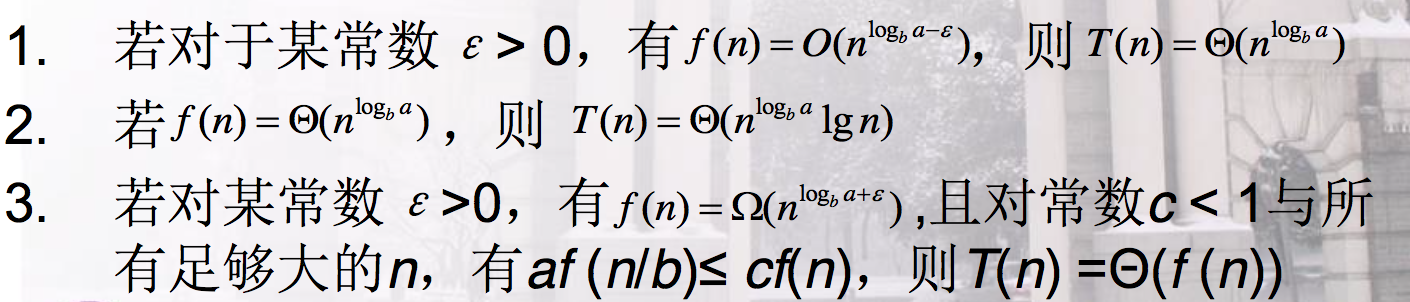
强行记住公式即可。不考虑证明。
2. 排序
堆。
堆虽然是一个树状数据结构,但实际上是用数组存的。1
2
3PARENT(i) = int(i/2)
LEFT(i) = 2*i
RIGHT(i) = 2*i +1
最大堆父节点一定大于等于孩子;最小堆反之。
最大堆的调整是从上往下调整的。调整整个堆,需要对前n/2个节点(逆序)调整一次。所以上界是nlgn。
1 | heap-size[A] ← length[A] |
证明的是每次循环开始的时候,都是一个最大堆的根。
简单上界很好判断,正如前文所说,nlgn,但不是紧确的。但通过求和计算,发现运行时间的界为O(n)
堆排序
A[1]是最大的。所以把A[1]与A[n]交换,再把A[1..n-1]恢复成一个堆。依次类推。复杂度为nlgn。
优先队列
可以用堆实现。1
2
3
4MAXIMUM: O(1)
EXTRACT-MAX: O(lgn)
INSERT-KEY: O(lgn)
INCREASE-KEY: O(lgn)
快排
平均性能最好,期望运行时间nlgn,最坏情况较差。
每次划分都是1, n-1,复杂度为n的平方。
只要按比例划分,都是nlgn。
加的优化是随机算法。用一个随机的数进行partition。
比较排序的下界
用决策树模型,因为有n!种排列可能,每一个都需要在一个叶子节点中出现。之前说过log(n!) 复杂度为nlgn。所以树的高度至少为nlgn。
计数排序
比较排序不是唯一的方法。计数排序可以达到o(n)的复杂度。基本思想是对于每一个数,求小于该数的元素的个数。
1 | for i←0 to k |
最后一个循环使用downto的原因是,当值相同的时候,输出顺序和输入顺序的结果是一样的。这种属性称之为稳定的排序。
基数排序
基数排序和我们日常中排数字的概念差不多。按照位,一位一位的用一种稳定排序算法排序。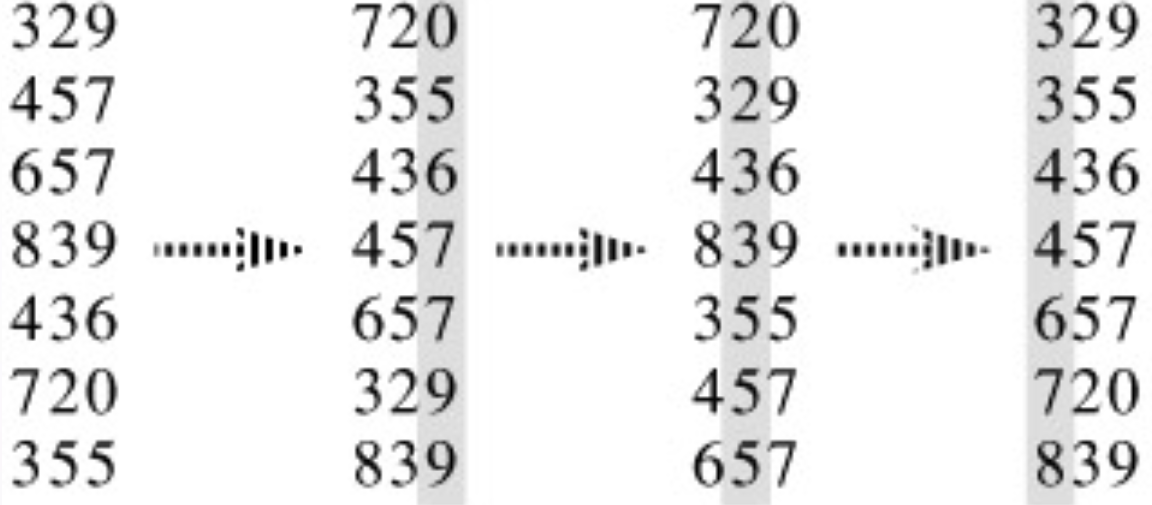
n个d位数,d介于0-k之间。排序时间O(d(n+k))
如果连续r位,合并为一个数字,(b/r)(n+2^r):如果b< lg(n), r=b,直接O(n); 如果 b>lg(n),r取lg(n),结果为bn/lgn。
注意点:
- 常见情况是O(n)
- 但是常数因子较大
- 不是原地排序,耗内存。
桶排序
原理很简单,可以说是分冶的极致。但是每个桶里的数很少,很快就排完了。1
2
3
4
5
6n←length[A]
for i← 1 to n
do insert A[i] into list B[nA[i]]
for i← 0 to n-1
do sort list B[i] with insertion sort
concatenate the lists B[0],B[1],...,B[n-1]together in order
算出来期望是O(n)。
中位数和顺序统计
最大值和最小值
两两比较,小的和当前最小值比,大的和当前最大值比。3(n/2)的复杂度。
顺序统计学
输入n和i,求一个数,使得i-1个数比它小。
随机选择:借用快排的思想,但是每次只需要执行其中的一边。所以期望的复杂度是O(n)。数学证明略。
最坏情况的线性选择。
- 将输入数组的n个元素划分为⌈n/5⌉组,每组 5个元素,且至多只有一个组由剩下的n mod 5个元素组成
- 寻找⌈n/5⌉个组中每一组的中位数,首先对 每组中的元素(至多为5个)进行插入排序, 然后从排序过的序列中选出中位数
- 对第2步中找出的⌈n/5⌉个中位数,递归调用 SELECT以找出其中位数x。(如果有偶数个 中位数,根据约定,x是下中位数)
- 利用修改过的PARTITION过程,按中位数 的中位数x对输入数组进行划分。让k比划分 低区的元素数目多1,所以x是第k小的元素, 并且有n-k个元素在划分的高区
- 如果i=k,则返回x; 否则如果i
前三步只是用来找partition时候划分的数,第4步和第5步才是原来随机选择的办法。最后证明,在最坏的情况下,也能保证线性的时间。
3. 图计算
图的表示
G = {V, E},邻接表或者邻接矩阵。邻接表的存储空间为|E|,邻接矩阵为|V|*|V|
BFS
通过构建一个广度优先树。扫描每个节点的邻点,如果是白色,就在树中添加一个边,且把这个节点加入到准备队列里。
构建的搜索树可能不同,但是深度肯定是一样的。
复杂度:O(V+E)
算出来的d值,一定是距离s的最短路径。证明略。
DFS
1 | for each vertex u ∈ V [G] |
所以最后获得的是一个深度优先森林。复杂度也是O(V+E).
d[u]和f[u]构成了一个区间,要么完全没关系,要么完全覆盖,由此判断两个点的关系。
拓扑排序
定义:图的所有顶点沿水平排列,所有的有向边均从左指向右。
做法:用DFS,一个顶点完成的时候(f)插到链表前端。
引理:有向图G无回路当且仅当对G进行深度优先搜索没有得到反向边
证明拓扑排序就按照f的时间比较即可。
强连通分支
定义:任何两个顶点互相可达,称为强连通图。
G的强连通子图称为强连通分支。
- 调用DFS(G)计算每个节点完成时间f(u)
- 求图的转置。
- 调用DFS(G^T),主循环里按f(u)递减的顺序考虑各个顶点。
- 输出每个深度优先森林的顶点。
收缩之后得到一个分支图。分支图一定是无环的。复杂度为O(V+E)
算法证明
可以在第三行的G^T做归纳。可以证明每一颗树的节点都形成一个强连通分支。归纳假设是前k个树都是强连通分支。
k=0的时候,没有任何树,显而成立。
归纳假设前k个树都是强连通,现在考虑第k+1个树。设顶点为u,位于强连通分量C中。
根据优先根的选择方式,对于其他任何将要访问的强连通分支,f[u] = f(C) > f(C’).当搜到u的时候,C中其他顶点都是白色的。所以C这棵深度优先树,u为顶点。
根据推论,如果在G^T中存在(u,v),u在C中,v在C’中,那么f(C) < f(C’)。又因为f(C)是当前最大的了,所以不会存在u指向其他没有分离出来的C‘。也就是说,离开该C的边都是指向已经搜索过的边了。
所以,根为u的深度优先树恰好是一个强连通分支。
搜索问题
求一个n元组的解使得准则函数最大化。变量取值范围为有限集合。
解可以看做是一个空间状态树。
如果暴利搜索太慢了,所以会用到一些剪枝的方法。而要用好剪枝,需要构造好树的结构和搜索顺序。
回溯法
略
分支定界法
搜索的时候,一个节点只有一次能成为活跃节点(生成所有的子节点),同时会有一个下限(求最小化问题)或者上限(求最大化问题),用来方便剪枝。
应该会考,所以看下ppt上的例题。尤其是旅行商问题。精妙之处在于选择一个点,确定走不走这条路。在此这个地方分叉为两个节点。
启发式搜索
略
4. 动态规划
动态规划的问题核心在于划分子问题。
钢条问题
核心点在于,问题的分析。先切一刀,左边的再也不切了,右边还有可能切。所以分成了若干个子问题去求解。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18MEMOIZED-CUT-ROD(p, n)
let r[0...n] be a new array
for i=0 to n
r[i]= MIN_INT
return MEMOIZED-CUT-ROD-AUX(p, n, r)
MEMOIZED-CUT-ROD-AUX(p, n, r)
if r[n]>=0
return r[n]
if n==0
q=0
else
q= MIN_INT
for i= 1 to n
q=max(q,p[i]+MEMOIZED-CUT-ROD-AUX(p,n-i,r))
r[n]=q
return q
也可用自底向上,只不过不用递归了。
1 | let r[0...n] be a new array |
保留切割信息也很简单,就是保留切割n的时候,第一刀下在哪里。在print的时候,逆序打印出来即可。
矩阵链乘法
这个核心在于,子问题是A[i..j]。子问题的个数只有2^n个。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//自底向上
MATRIX-CHAIN-ORDER(p)
n ← length[p] - 1
for i ← 1 to n
do m[i, i] ← 0
for l ← 2 to n // l is the chain length.
do for i ← 1 to n - l + 1 // A[i..j]
do j ← i + l - 1
m[i, j] ← ∞
for k ← i to j - 1
do q ← m[i, k] + m[k+1, j] + pi-1pkpj
if q < m[i, j]
then m[i, j] ← q
s[i, j] ← k
return m and s
动态规划问题的特征
有最优子结构的问题,一定可以用动态规划来做;反之,不一定。算法复杂度为子问题个数*每个子问题的选择个数。如钢条问题为n的平方,矩阵问题为n的三次方。
所以,对于无权最短路径,有最优子结构;无权最长路径,无最优子结构。
子问题独立:一个子问题的解,不会影响同一个问题中另外一个子问题的解。如无权最长路径,确定前一个最长子路,后面一个子路不能和前面的交叉,于是就有了影响。
另外一个基本性质是子问题的重叠性;即子问题不用重新计算。
最长公共子序列
1 | if (i == 0 || j == 0) |
最优二叉搜索树
有点类似于矩阵链乘。有子树K[i..j],d[i-1,j],该子树肯定是最优的。
所以看连续范围内的搜索代价问题。
e[i, j] = q[i-1] if j==i-1
e[i, j] = min{e[i, r-1] + e[r+1, j] + w[i, j]} if i<= j
最短路径
这个和图算法有点区别。设 $l_{i,j}^{(m)}$ 为从i到j至多包含m条边的最短路。可以构建递归式。
$$ l_{i,j}^{(m)} = min ( l_{i,k}^{(m-1)} + w_{k,j} ) $$
有点类似于矩阵乘法,只要算出$l^{n-1}$来即可。因为之后肯定都一样。
可以根据传统的矩阵结合律,先算l(1),再算l(2),l(4),l(8)…所以复杂度时间降为$n^3lgn$。
Floyd-Warshall算法
该算法是一种升级版,可以将复杂度降到n的三次方。基于的观察是i到j,所有中间节点都属于{1,2,3,…,k}时候的最短路径。
- 如果k不是中间节点,那么中间节点都在{1,2,3,…,k-1}中。
- 如果k是中间节点,可以分成两个部分,i到k和k到j,同样,这两条路的中间节点都不会经过k,只属于{1,2,3,…,k-1}
所以定义$d_{ij}^{(k)}$为满足中间节点都在{1,2,3,…,k}的最短路的权值。如果集合为空,表示没有中间节点。
- if k=0 $d_{ij}^{(k)} = w_{ij}$
- else $d_{ij}^{(k)} = min(d_{ij}^{(k-1)}, d_{ik}^{(k-1)}+d_{kj}^{(k-1)} )$
每一轮k,只需要n的平法次复杂度即可。而不像原来需要n的三次方。